Common wisdom states that an ML engineer spends about 80% of the time on data preprocessing and feature engineering. I buy the feature engineering part because good features are essential for a good model. However, I’m not convinced about data prepossessing anymore because I have seen the same opening ritual in nearly every new FinTech ML project:
- Find a quality data source.
- Acquire or download data.
- Ingest data into a DB or convert to flat files.
- Write a bunch of scripts or SQL queries to organize data.
- Finally, start feature engineering. Wait, what? Why aren’t the data standardized?
It’s 2023, and none of this makes sense, yet it’s a prevalent practice. However, you cannot integrate dozens of crypto exchanges yourself because there is no time and budget for that, meaning you usually get a data provider and get to work. When you look at Crypto data providers, you find roughly three categories:
-
From Wall Street for Wall Street. Think Bloomberg, Refinitiv, ICE Data, or OneTick. These are good but very expensive, and you’re not done with buying their solution because the next item on your list is building a matching data warehouse if you haven’t one yet. If you turn up in an organization with its data warehouse in order and OneTick access, you may not know how lucky you are.
-
Data directly from the exchange. The only difference is that you have to pay for regulated exchange data while you get crypto data for free. The catch, though, is that while Wall Street has standardized ticker symbols a long time ago, that has not happened yet in Crypto. The problem with inconsistent ticker symbols across exchanges is that integrating multiple crypto exchanges becomes a normalization nightmare.
-
Various specialized solutions. Luckily, Crypto, with its open data spirit, has led to the formation of several reasonably priced or even free data providers. There is CoinMarketCap, CrytpoDownload, CoinGecko, CoinApi, and more. These sound like a perfect solution to the previously mentioned normalization nightmare. Well, not so fast.
Data Requirements
That looks reasonable at first sight. But before deciding on a data provider, take a closer look at your requirements of why you need crypto data. There are roughly three categories of crypto data usage. First, you build a trading system. Second, you build some crypto analytics, and third, you do some research either for yourself, in the industry, or academically. For now, let’s exclude research and instead focus on the requirements of crypto trading and crypto analytics because, unlike research, these are usually in 24/7 operations and, therefore, have unambiguous requirements.
Crypto Trading Systems
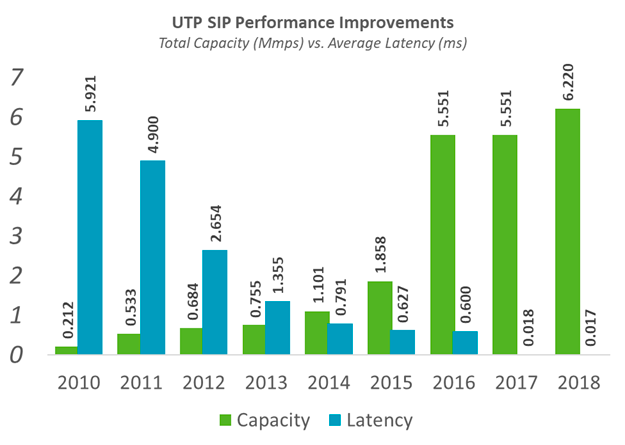
All trading systems operate on real-time event-based message passing for performance reasons. The consequence is that you usually connect data via a message broker to the analytic, monitoring, or trading system and focus on your work. A relatively common architectural pattern for trading systems is to connect all system parts via a standardized message bus using a binary-encoded message format. The reason for binary message data is that latency scales inversely to throughput. That means the lower the throughput, the higher the latency. Because all trading systems aim to minimize latency, these systems aim for the highest possible message throughput. One way to reach maximum throughput is to increase connection capacity because traffic through an uncongested connection is always faster than through a fully saturated link. The chart below shows the relationship between capacity (implicit throughput) and latency. Another way to improve latency is to cut the distance data travel, usually accomplished via collocating the trade engine in the same data center as the exchange.
Crypto Data Analytics
Even if you don’t build a trading system, the same architecture pattern applies to real-time analytics that operate on data streams. Anomaly detection is an excellent example because it’s only valuable when it detects something as it happens, and to do so, you analyze a data stream in real-time. Trend analytics is another topic that works best on real-time data because you want to jump on the trend and ride the wave when it unfolds, and to do so, you analyze a real-time data stream. Risk management, as another example, is useless if it’s not real-time because getting the warning after the market has tanked bears no value. Even something as simple as embedding a BTC ticker on a website is technically a data stream. You might think that all adds up, meaning you just connect to a data stream and call it a day. Right..?
Issues with crypto Data Providers
Most crypto data providers somehow came up with the brilliant idea of REST APIs for crypto data, even though virtually all crypto exchanges provide real-time data streams. There are several problems with REST APIs for FinTech, so let’s look at the most annoying issues.
Performance and Latency
Even when you ignore the feasibility for the moment, whenever you open an HTTP request, you have to wait for a reply, which adds to the total latency. Next, you parse a JSON payload, convert it into something that fits your data format, and send it to your system, which adds additional latency for no reason. Then, you have the problem that you consistently open and close network connections, so this isn’t exactly great for performance and latency either. It’s mind-boggling that anyone considers this a good idea, but apparently, many folks thought it is because last time I checked multiple crypto data providers, they all use REST by default.
Request limits
When you pull a REST API for crypto data, you set a Chron job to call an API endpoint, say every minute, to get the latest data. There is a slight synchronization task here, meaning you have to ensure the pulling server has an NTP synced clock to ensure you are not pulling a millisecond before the API has published its data, but these can be solved. The blocker is the prevalent request limit imposed by crypto data providers that charge for every request more than the limit. If you pull for 500 instruments, well, you may stay within the limit, but if you get, say, a thousand, good luck with that. Then, you already sit down and crunch the numbers to determine whether you stay within the limit or better upgrade to the next tier. Calculating API requests takes a few considerations because, usually, a data provider uses a global API request counter, so you count all other API calls in addition to the data polling to determine your total number of API calls. If you make a calculation mistake, your next bill will set someone straight. Worse yet, if your system has clients with irregular usage patterns, well, one significant usage spike unavoidably results in another bill that will set someone straight.

Feasibility
Realistically, how often can you call a REST endpoint before triggering abuse protection that would ban your IP? For Binance, the hard rate limit is 1,200 request weight per minute or about 20 requests per second. Most data providers usually have less generous limits but gladly increase the limit for a fee. If you ever try to track all Binance markets per REST API, you generate more requests per minute than even the generous Binance API gives you. In other words, this is simply infeasible without hacking around or paying a lot more for the excessive usage tier.
Backtesting pain
The main property of message-based systems is that you test them with, well, a message. And yet, the crypto data providers provide a REST API to download historical data in bulk. Then you have a gigantic JSON payload. Now what? What is the next step? Remember the ritual mentioned at the beginning because that is what you do: you collect data, convert, ingest, and query data to generate a data stream for backtesting.
Issues with Time series Databases
Next on the list is the realization that not every self-proclaimed time-series database delivers practical performance. By that, I mean nothing too crazy, just a reasonable time to ingest a million rows. In reality, you ingest way more data, usually batched in hundreds of millions of rows. Still, by simple arithmetic, you can estimate the total ingestion time from a single 1 million row insert.
TimescaleDB
Yet, inserting a million row is already too much for TimescaleDB, not to mention when things get realistic by inserting 100 million rows. The TimescaleDB company would almost certainly contest these reports and point out that, it’s been improved in a newer version and if you were to make a proper benchmark on a beefy cloud instance, you see miraculous performance. Obviously, if a database cannot perform well on a server with 32 CPU’s and 192 GB memory, then it shouldn’t exists in the first place. I admit, I was tempted to believe this line of reasoning, but new version after new version, insertion performance on my development machine never really changed and, get this, same machine, different database, ten times faster inserts.

To speed up lackluster query performance, you could set up Redis, cache query results, and call it a day. But then you also have to develop a heuristic to determine if query results have changed, and in case they have, you are back to square one and load from the same slow DB. How slow, you may ask? A million rows from a parquet file load up to ten times faster than TimescaleDB. I know that from experience because, in one project, I replaced TimescaleDB with parquet files.
In all fairness, TimescaleDB is a good database for less demanding projects. Plus, you can cluster the open-source version, an exception nowadays. However, there is only so much you can patch up an elephant, and ultimately, one has to admit that the underlying Postgres storage engine was never designed for large-scale real-time time-series data.
Influx
I looked at Influx, too, but back when version 1.8 / 2 was around, performance wasn’t any good. The much-improved version 3 is only available via the vendor’s cloud service. You could forgive a newcomer this blunder, but Influx has been around for over ten years and still clings to a restrictive distribution model.
QuestDB
There is the new kid on the block, QuestDB. It’s a genuinely great database, and insertion performance is on a new level. I tried it multiple times, and the performance is outstanding, and in terms of functionality, every major release closes the gap further. It’s the only database I want to love for getting so much right from the beginning, and yet what makes it so hard is the critical things it lacks. For example, SQL functions such as sliding windows are still missing, and somehow, importing CSV still causes several issues. I have experienced some of these issues and eventually wrote a tiny utility that reads a data file and inserts vial the IPL protocol at insane speed. Personally, I would not overrate the CSV issues because the big ones might have been already fixed and writing a utility for data import really is no big deal either. On that note, the QuestDB SDK is really good, the code examples work out of the box, and you get things done really fast so all in all the developer experience is great.
Somehow, the open-source version cannot be clustered, probably to boost their enterprise sales. As QuestDB tends to update fast and often, adding more missing features leads to the main problem with finance data: You cannot shut down the database cluster. Digital markets operate 24/7, meaning you cannot shut down the database cluster, update each node, and restart. You would need a rolling cluster upgrade mechanism that keeps the cluster available during the upgrade process, which isn’t there yet.
That said, QuestDB only launched officially in 2020(!); therefore, it is remarkable how good this DB already is at this early stage. Unlike TimescaleDB, QuestDB delivers truly outstanding performance, and unlike Influx, you pull a docker image, start coding, and deploy the latest version to your environment of choice. Give it another year or two, and QuestDB may become the ultimate rising star for serious performance on time-series data. If its short history is even remotely indicative of what is to come, I am optimistic about QuestDB securing a stronghold in the market.
MS SQL Server
I can only briefly mention the MS SQL server because I don’t have any first-hand experience with it. However, I know from someone who operates an MS SQL server with multiple TB of time series data that “TimescaleDB is no faster,” according to his benchmarks. At least it’s reassuring that Microsoft still defends its reputation of not standing out.
Here is the catch, though: at some point, things get real, the rubber hits the road, and suddenly you realize that those already in the Microsoft .NET ecosystem choose SQL server any given day because, well, the alternative is a broken elephant, an inaccessible influx, and a not-yet-fully-ready quest. However, if you chose SQL Server on Azure, then you have to deal with Azure SQL server occasionally going down, sometimes for hours, because it’s still Microsoft.

Why do you even need a market data database in the first place? Because the system you are working on requires substantial testing on actual data. That is one way to look at the situation. Another way to look at the situation is that your data provider does not provide a convenient way to replay historical data streams. Whether you build a trading system, data analytics, or anything in between, your data science would be much easier when you connect a data source, work with replayed historical data until things are ready, and then deploy your system and switch over to the live stream. Because you can’t do this, you encounter madness everywhere.
Where does this leave us?
Crypto exchanges can’t agree on interoperable data standards and normalized ticker symbols. Crypto data providers think that rate-limited REST APIs are a good idea for an industry relying on event-based message systems, and suddenly, you are busy cobbling systems together that operate on the opposite end of the spectrum.
For databases, things get even more weird than you could imagine in your wildest dreams. Choose TimescaleDB, and you can cluster, but performance tanks to the bottom. Choose Influx, and good luck with vendor lock-in. Choose QuestDB, and you can’t cluster unless you buy the enterprise version, but even then, you can’t upgrade the cluster without shutting it down. Choose MS SQL server, you can cluster, you get rolling cluster upgrades with always-on, and you can calculate moving averages, but you are no faster than TimeScaleDB, and you better have a working backup.
Remember, just because people do things in a certain way and call it normal doesn’t make it so.
At this point, have you already started with your feature engineering? Have you written one line of code? Have you tested one new idea? Probably not. If you’ve already tackled the topics listed above and think it’s a good investment of your engineering time, go ahead and build it all in-house, but make sure to budget for the maintenance work that is always needed. To solve this problem, I have started working on DexStream.ai, which connects you to multiple crypto exchanges, streaming real-time or historical data through one API for unlimited data streaming. If you’re interested, sign up to join the future of streaming crypto data.
Join the Waitlist